optuna.samplers¶
-
class
optuna.samplers.BaseSampler[source]¶ Base class for samplers.
Optuna combines two types of sampling strategies, which are called relative sampling and independent sampling.
The relative sampling determines values of multiple parameters simultaneously so that sampling algorithms can use relationship between parameters (e.g., correlation). Target parameters of the relative sampling are described in a relative search space, which is determined by
infer_relative_search_space().The independent sampling determines a value of a single parameter without considering any relationship between parameters. Target parameters of the independent sampling are the parameters not described in the relative search space.
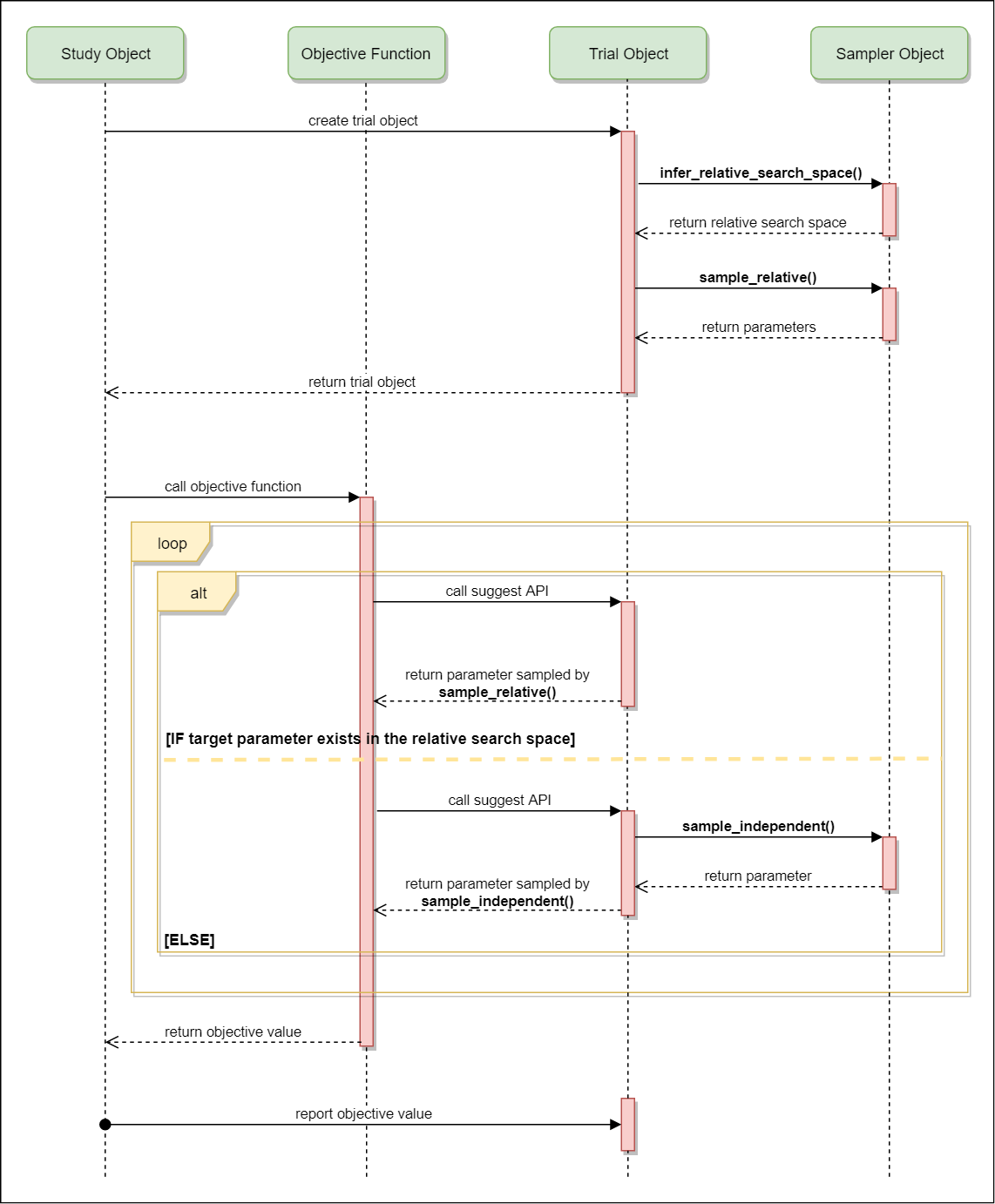
More specifically, parameters are sampled by the following procedure. At the beginning of a trial,
infer_relative_search_space()is called to determine the relative search space for the trial. Then,sample_relative()is invoked to sample parameters from the relative search space. During the execution of the objective function,sample_independent()is used to sample parameters that don’t belong to the relative search space.The following figure depicts the lifetime of a trial and how the above three methods are called in the trial.
-
abstract
infer_relative_search_space(study, trial)[source]¶ Infer the search space that will be used by relative sampling in the target trial.
This method is called right before
sample_relative()method, and the search space returned by this method is pass to it. The parameters not contained in the search space will be sampled by usingsample_independent()method.- Parameters
study – Target study object.
trial – Target trial object. Take a copy before modifying this object.
- Returns
A dictionary containing the parameter names and parameter’s distributions.
See also
Please refer to
intersection_search_space()as an implementation ofinfer_relative_search_space().
-
reseed_rng() → None[source]¶ Reseed sampler’s random number generator.
This method is called by the
Studyinstance if trials are executed in parallel with the optionn_jobs>1. In that case, the sampler instance will be replicated including the state of the random number generator, and they may suggest the same values. To prevent this issue, this method assigns a different seed to each random number generator.
-
abstract
sample_independent(study, trial, param_name, param_distribution)[source]¶ Sample a parameter for a given distribution.
This method is called only for the parameters not contained in the search space returned by
sample_relative()method. This method is suitable for sampling algorithms that do not use relationship between parameters such as random sampling and TPE.Note
The failed trials are ignored by any build-in samplers when they sample new parameters. Thus, failed trials are regarded as deleted in the samplers’ perspective.
- Parameters
study – Target study object.
trial – Target trial object. Take a copy before modifying this object.
param_name – Name of the sampled parameter.
param_distribution – Distribution object that specifies a prior and/or scale of the sampling algorithm.
- Returns
A parameter value.
-
abstract
sample_relative(study, trial, search_space)[source]¶ Sample parameters in a given search space.
This method is called once at the beginning of each trial, i.e., right before the evaluation of the objective function. This method is suitable for sampling algorithms that use relationship between parameters such as Gaussian Process and CMA-ES.
Note
The failed trials are ignored by any build-in samplers when they sample new parameters. Thus, failed trials are regarded as deleted in the samplers’ perspective.
- Parameters
study – Target study object.
trial – Target trial object. Take a copy before modifying this object.
search_space – The search space returned by
infer_relative_search_space().
- Returns
A dictionary containing the parameter names and the values.
-
abstract
-
class
optuna.samplers.GridSampler(search_space)[source]¶ Sampler using grid search.
With
GridSampler, the trials suggest all combinations of parameters in the given search space during the study.Example
import optuna def objective(trial): x = trial.suggest_uniform('x', -100, 100) y = trial.suggest_int('y', -100, 100) return x ** 2 + y ** 2 search_space = { 'x': [-50, 0, 50], 'y': [-99, 0, 99] } study = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space)) study.optimize(objective, n_trials=3*3)
Note
GridSamplerraises an error if all combinations in the passedsearch_spacehas already been evaluated. Please make sure that unnecessary trials do not run during optimization by properly settingn_trialsin theoptimize()method.Note
GridSamplerdoes not take care of a parameter’s quantization specified by discrete suggest methods but just samples one of values specified in the search space. E.g., in the following code snippet, either of-0.5or0.5is sampled asxinstead of an integer point.import optuna def objective(trial): # The following suggest method specifies integer points between -5 and 5. x = trial.suggest_discrete_uniform('x', -5, 5, 1) return x ** 2 # Non-int points are specified in the grid. search_space = {'x': [-0.5, 0.5]} study = optuna.create_study(sampler=optuna.samplers.GridSampler(search_space)) study.optimize(objective, n_trials=2)
- Parameters
search_space – A dictionary whose key and value are a parameter name and the corresponding candidates of values, respectively.
Note
Added in v1.2.0 as an experimental feature. The interface may change in newer versions without prior notice. See https://github.com/optuna/optuna/releases/tag/v1.2.0.
-
class
optuna.samplers.RandomSampler(seed=None)[source]¶ Sampler using random sampling.
This sampler is based on independent sampling. See also
BaseSamplerfor more details of ‘independent sampling’.Example
import optuna from optuna.samplers import RandomSampler def objective(trial): x = trial.suggest_uniform('x', -5, 5) return x**2 study = optuna.create_study(sampler=RandomSampler()) study.optimize(objective, n_trials=10)
- Args:
seed: Seed for random number generator.
-
reseed_rng() → None[source]¶ Reseed sampler’s random number generator.
This method is called by the
Studyinstance if trials are executed in parallel with the optionn_jobs>1. In that case, the sampler instance will be replicated including the state of the random number generator, and they may suggest the same values. To prevent this issue, this method assigns a different seed to each random number generator.
-
class
optuna.samplers.TPESampler(consider_prior=True, prior_weight=1.0, consider_magic_clip=True, consider_endpoints=False, n_startup_trials=10, n_ei_candidates=24, gamma=<function default_gamma>, weights=<function default_weights>, seed=None)[source]¶ Sampler using TPE (Tree-structured Parzen Estimator) algorithm.
This sampler is based on independent sampling. See also
BaseSamplerfor more details of ‘independent sampling’.On each trial, for each parameter, TPE fits one Gaussian Mixture Model (GMM)
l(x)to the set of parameter values associated with the best objective values, and another GMMg(x)to the remaining parameter values. It chooses the parameter valuexthat maximizes the ratiol(x)/g(x).For further information about TPE algorithm, please refer to the following papers:
Example
import optuna from optuna.samplers import TPESampler def objective(trial): x = trial.suggest_uniform('x', -10, 10) return x**2 study = optuna.create_study(sampler=TPESampler()) study.optimize(objective, n_trials=10)
- Parameters
consider_prior – Enhance the stability of Parzen estimator by imposing a Gaussian prior when
True. The prior is only effective if the sampling distribution is eitherUniformDistribution,DiscreteUniformDistribution,LogUniformDistribution,IntUniformDistribution, orIntLogUniformDistribution.prior_weight – The weight of the prior. This argument is used in
UniformDistribution,DiscreteUniformDistribution,LogUniformDistribution,IntUniformDistribution,IntLogUniformDistribution, andCategoricalDistribution.consider_magic_clip – Enable a heuristic to limit the smallest variances of Gaussians used in the Parzen estimator.
consider_endpoints – Take endpoints of domains into account when calculating variances of Gaussians in Parzen estimator. See the original paper for details on the heuristics to calculate the variances.
n_startup_trials – The random sampling is used instead of the TPE algorithm until the given number of trials finish in the same study.
n_ei_candidates – Number of candidate samples used to calculate the expected improvement.
gamma – A function that takes the number of finished trials and returns the number of trials to form a density function for samples with low grains. See the original paper for more details.
weights –
A function that takes the number of finished trials and returns a weight for them. See Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures for more details.
seed – Seed for random number generator.
-
static
hyperopt_parameters()[source]¶ Return the the default parameters of hyperopt (v0.1.2).
TPESamplercan be instantiated with the parameters returned by this method.Example
Create a
TPESamplerinstance with the default parameters of hyperopt.import optuna from optuna.samplers import TPESampler def objective(trial): x = trial.suggest_uniform('x', -10, 10) return x**2 sampler = TPESampler(**TPESampler.hyperopt_parameters()) study = optuna.create_study(sampler=sampler) study.optimize(objective, n_trials=10)
- Returns
A dictionary containing the default parameters of hyperopt.
-
reseed_rng() → None[source]¶ Reseed sampler’s random number generator.
This method is called by the
Studyinstance if trials are executed in parallel with the optionn_jobs>1. In that case, the sampler instance will be replicated including the state of the random number generator, and they may suggest the same values. To prevent this issue, this method assigns a different seed to each random number generator.
-
class
optuna.samplers.CmaEsSampler(x0: Optional[Dict[str, Any]] = None, sigma0: Optional[float] = None, n_startup_trials: int = 1, independent_sampler: Optional[optuna.samplers._base.BaseSampler] = None, warn_independent_sampling: bool = True, seed: Optional[int] = None, *, consider_pruned_trials: bool = False)[source]¶ A Sampler using CMA-ES algorithm.
Example
Optimize a simple quadratic function by using
CmaEsSampler.import optuna def objective(trial): x = trial.suggest_uniform('x', -1, 1) y = trial.suggest_int('y', -1, 1) return x ** 2 + y sampler = optuna.samplers.CmaEsSampler() study = optuna.create_study(sampler=sampler) study.optimize(objective, n_trials=20)
Please note that this sampler does not support CategoricalDistribution. If your search space contains categorical parameters, I recommend you to use
TPESamplerinstead. Furthermore, there is room for performance improvements in parallel optimization settings. This sampler cannot use some trials for updating the parameters of multivariate normal distribution.See also
You can also use
optuna.integration.CmaEsSamplerwhich is a sampler using cma library as the backend.- Parameters
x0 – A dictionary of an initial parameter values for CMA-ES. By default, the mean of
lowandhighfor each distribution is used.sigma0 – Initial standard deviation of CMA-ES. By default,
sigma0is set tomin_range / 6, wheremin_rangedenotes the minimum range of the distributions in the search space.seed – A random seed for CMA-ES.
n_startup_trials – The independent sampling is used instead of the CMA-ES algorithm until the given number of trials finish in the same study.
independent_sampler –
A
BaseSamplerinstance that is used for independent sampling. The parameters not contained in the relative search space are sampled by this sampler. The search space forCmaEsSampleris determined byintersection_search_space().If
Noneis specified,RandomSampleris used as the default.See also
optuna.samplersmodule provides built-in independent samplers such asRandomSamplerandTPESampler.warn_independent_sampling –
If this is
True, a warning message is emitted when the value of a parameter is sampled by using an independent sampler.Note that the parameters of the first trial in a study are always sampled via an independent sampler, so no warning messages are emitted in this case.
consider_pruned_trials –
If this is
True, the PRUNED trials are considered for sampling.Note
Added in v2.0.0 as an experimental feature. The interface may change in newer versions without prior notice. See https://github.com/optuna/optuna/releases/tag/v2.0.0.
Note
It is suggested to set this flag
Falsewhen theMedianPruneris used. On the other hand, it is suggested to set this flagTruewhen theHyperbandPruneris used. Please see the benchmark result for the details.
-
reseed_rng() → None[source]¶ Reseed sampler’s random number generator.
This method is called by the
Studyinstance if trials are executed in parallel with the optionn_jobs>1. In that case, the sampler instance will be replicated including the state of the random number generator, and they may suggest the same values. To prevent this issue, this method assigns a different seed to each random number generator.
-
class
optuna.samplers.IntersectionSearchSpace[source]¶ A class to calculate the intersection search space of a
BaseStudy.Intersection search space contains the intersection of parameter distributions that have been suggested in the completed trials of the study so far. If there are multiple parameters that have the same name but different distributions, neither is included in the resulting search space (i.e., the parameters with dynamic value ranges are excluded).
Note that an instance of this class is supposed to be used for only one study. If different studies are passed to
calculate(), aValueErroris raised.-
calculate(study: optuna.study.BaseStudy, ordered_dict: bool = False) → Dict[str, optuna.distributions.BaseDistribution][source]¶ Returns the intersection search space of the
BaseStudy.- Parameters
study – A study with completed trials.
ordered_dict – A boolean flag determining the return type. If
False, the returned object will be adict. IfTrue, the returned object will be ancollections.OrderedDictsorted by keys, i.e. parameter names.
- Returns
A dictionary containing the parameter names and parameter’s distributions.
-
-
optuna.samplers.intersection_search_space(study: optuna.study.BaseStudy, ordered_dict: bool = False) → Dict[str, optuna.distributions.BaseDistribution][source]¶ Return the intersection search space of the
BaseStudy.Intersection search space contains the intersection of parameter distributions that have been suggested in the completed trials of the study so far. If there are multiple parameters that have the same name but different distributions, neither is included in the resulting search space (i.e., the parameters with dynamic value ranges are excluded).
Note
IntersectionSearchSpaceprovides the same functionality with a much faster way. Please consider using it if you want to reduce execution time as much as possible.- Parameters
study – A study with completed trials.
ordered_dict – A boolean flag determining the return type. If
False, the returned object will be adict. IfTrue, the returned object will be ancollections.OrderedDictsorted by keys, i.e. parameter names.
- Returns
A dictionary containing the parameter names and parameter’s distributions.